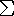 xy -
(x)(y)
xy -
(x)(y)
sqrt[n(
x2) -
(x)2] · sqrt[n(y2) -
(y)2]
Examples: one variable might be the number of hunters in a region and the other variable could be the deer population. Perhaps as the number of hunters increases, the deer population decreases. This is an example of a negative correlation: as one variable increases, the other decreases. A positive correlation is where the two variables react in the same way, increasing or decreasing together. Temperature in Celsius and Fahrenheit have a positive correlation.
How can you tell by inspection the type of correlation?
If the graph of the variables represent a line with positive slope, then
there is a positive correlation (x increases as y increases).
If the slope of the line is negative, then there is a negative correlation
(as x increases y decreases).
An important aspects of correlation is how strong it is. The strength of a correlation is measured by the correlation coefficient r. Another name for r is the Pearson product moment correlation coefficient in honor of Karl Pearson who developed it about 1900. There are at least three different formulae in common used to calculate this number and these different formulae somewhat represent different approaches to the problem. However, the same value for r is obtained by any one of the different procedures. First we give the raw score formula. n has the usual meaning of how many ordered pairs are in our sample. It is also important to recognize the difference between the sum of the squares and the squares of the sums!
|
r =
nxy -
(x)(y)
sqrt[n( x2) -
(x)2] · sqrt[n(y2) -
(y)2]
|
Next we present the deviation score formula. This formula is closer to the developmental history since it gives the average cross-product of the standard scores of the two variables, but in a computationally easier format.
|
r = xy
sqrt( x2
y2)
|
We need to make some notes regarding notation since the x and y variables in the formula above have been transformed from the original variables by subtracting their means.
Lastly we present the covariance formula, which is yet another approach. Covariances are commonly given between two variables and this is one reason why. (It should be noted that the size of the covariance is dependent on the units of measurement used for each variable. However, the correlation coefficient is not.)
|
r = sxy sxsy |
r is often denoted as rxy to emphasize the two variables under consideration. For samples, the correlation coefficient is represented by r while the correlation coefficient for populations is denoted by the Greek letter rho (which can look like a p). Be aware that the Spearman rho correlation coefficient also uses the Greek letter rho, but generally applies to samples and the data are rankings (ordinal data).
The closer r is to +1, the stronger the positive correlation is. The closer r is to -1, the stronger the negative correlation is. If |r| = 1 exactly, the two variables are perfectly correlated! Temperature in Celsius and Fahrenheit are perfectly correlated.
Formal hypothesis testing can be applied to r to determine how significant a result is. That is the subject of Hinkle chapter 17 and this lesson 12. The Student t distribution with n-2 degrees of freedom is used.
| Remember, correlation does not imply causation. |
A value of zero for r does not mean that there is no correlation, there could be a nonlinear correlation. Confounding variables might also be involved. Suppose you discover that miners have a higher than average rate of lung cancer. You might be tempted to immediate conclude that their occupation is the cause, whereas perhaps the region has an abundance of radioactive radon gas leaking from the subterranian regions and all people in that area are affected. Or, perhaps, they are heavy smokers....
r2 is frequently used and is called the coefficient of determination. It is the fraction of the variation in the values of y that is explained by least-squares regression of y on x. This will be discussed further in lesson 6 after least squares is introduced.
Correlation coefficients whose magnitude are between 0.9 and 1.0 indicate variables which can be considered very highly correlated. Correlation coefficients whose magnitude are between 0.7 and 0.9 indicate variables which can be considered highly correlated. Correlation coefficients whose magnitude are between 0.5 and 0.7 indicate variables which can be considered moderately correlated. Correlation coefficients whose magnitude are between 0.3 and 0.5 indicate variables which have a low correlation. Correlation coefficients whose magnitude are less than 0.3 have little if any (linear) correlation. We can readily see that 0.9 < |r| < 1.0 corresponds with 0.81 < r2 < 1.00; 0.7 < |r| < 0.9 corresponds with 0.49 < r2 < 0.81; 0.5 < |r| < 0.7 corresponds with 0.25 < r2 < 0.49; 0.3 < |r| < 0.5 corresponds with 0.09 < r2 < 0.25; and 0.0 < |r| < 0.3 corresponds with 0.0 < r2 < 0.09.
The formula for calculating the Spearman rho correlation coefficient is as follows.
|
rho (p) = 1 - 6d2
n(n2-1) |
n is the number of paired ranks and d is the difference between the paired ranks. If there are no tied scores, the Spearman rho correlation coefficient will be even closer to the Pearson product moment correlation coefficent. Also note that this formula can be easily understood when your realize that the sum of the squares from 1 to n can be expressed as n(n + 1)(2n + 1)/6. From this you can realize the least sum of d2 is zero and the greatest sum of d2 is twice the sum of the squares of the odd integers up to n/2 and this then scales such a sum between -1 and +1.
Example: Suppose we have test scores of 110, 107, 100, 96, 89, 78, 67, 66, and 49. These correspond with ranks 1 through 9. If there were duplicates, then we would have to find the mean ranking for the duplicates and substitute that value for our ranks. The corresponding first page score totals were: 29, 32, 27, 29, 25, 25, 21, 26, 22. Thus these ranks are as follows: 2.5, 1, 4, 2.5, 6.5, 6.5, 9, 5, 8. (Note that if we reversed the order, assigning the ranks from low to high instead of high to low, the resulting Spearman rho correlation coefficient would reverse sign.)
We have constructed a table below from the information above. We have added additional columns of d and d2 for ease in calculating the Spearman rho. Using the Spearman rho formula we get 1-6(24)/(9(80)) = 0.80.
| Total (x) | page 1 (y) | x rank | y rank | d | d2 | xy | x2 | y2 |
|---|---|---|---|---|---|---|---|---|
| 110 | 29 | 1 | 2.5 | -1.5 | 2.25 | 3190 | 12100 | 841 |
| 107 | 32 | 2 | 1 | 1 | 1 | 3424 | 11449 | 1024 |
| 100 | 27 | 3 | 4 | -1 | 1 | 2700 | 10000 | 729 |
| 96 | 29 | 4 | 2.5 | 1.5 | 2.25 | 2784 | 9216 | 841 |
| 89 | 25 | 5 | 6.5 | -1.5 | 2.25 | 2225 | 7921 | 625 |
| 78 | 25 | 6 | 6.5 | -0.5 | 0.25 | 1950 | 6084 | 625 |
| 67 | 21 | 7 | 9 | -2 | 4 | 1407 | 4489 | 441 |
| 66 | 26 | 8 | 5 | 3 | 9 | 1716 | 4356 | 676 |
| 49 | 22 | 9 | 8 | 1 | 1 | 1078 | 2401 | 484 |
| --- | --- | ----- | ---- | ----- | ----- | ---- | ||
| 762 | 236 | :sums: | 0 | 24 | 20474 | 68016 | 6286 | |
As the homogeneity of a group increases, the variance decreases and the magnitude of the correlation coefficient tends toward zero. It is thus imperative on the researcher to ensure enough heterogeneity (variation) so that a relationship can manifest itself. In general, the correlation coefficient is not affected by the size of the group.
| BACK | HOMEWORK | ACTIVITY | CONTINUE |
|---|